Machine Learning for Optimization
Research on integrating Machine Learning (ML) into designing efficient and robust meta-heuristics has become increasingly popular in recent years. At Solvice, we maintain our commitment to staying at the forefront of optimization technology by incorporating state-of-the-art ML techniques into our solver platform. The academic community recognizes three primary classes of ML methods that enhance metaheuristics. Problem-level data-driven metaheuristics leverage ML to model the optimization problem itself, including objective functions and constraints. These approaches assist in landscape analysis and help decompose complex problems into manageable components. Low-level data-driven metaheuristics focus on improving individual search components within the metaheuristic framework. ML drives various elements such as solution initialization through construction heuristics and search variation operators like neighborhoods in local search or mutation and crossover in evolutionary algorithms. The technology also optimizes parameter tuning across the metaheuristic. High-level data-driven metaheuristics address the selection and generation of metaheuristics themselves, enabling the design of sophisticated hybrid and parallel cooperative approaches. We distinguish between offline and online learning paradigms in our implementation. Offline data-driven metaheuristics complete the ML process before solving begins, building models from historical data to inform future optimization decisions. Online data-driven metaheuristics gather knowledge dynamically during the search process, adapting their strategies based on real-time insights from the current problem instance.Building Robust Solvers
Solvice builds APIs around solvers that tackle diverse planning and optimization challenges. Our customer base spans logistics providers, field service companies, warehouses, retail operations, independent software vendors, and software-as-a-service planning platforms. Our solver platform processes dynamic inputs of varying sizes and complexities without prior knowledge of incoming requests. This unpredictability demands solvers that combine robustness with efficiency and speed. Robustness in optimization manifests at two critical levels. First, we ensure robustness regarding problem size by maintaining linear solve time scaling as instances grow linearly while preserving solution quality. Second, we achieve robustness across problem variations, where instances of similar size may exhibit vastly different characteristics due to parameter differences. Both criteria prove essential for any optimization service, though few platforms achieve them consistently. We maintain robustness through continuous examination of every optimization request entering our system. Our offline testing framework identifies optimal parameterization for diverse problem types, ensuring we always apply the best parameter combinations. This approach exemplifies low-level data-driven metaheuristic optimization, where we predict ideal hyperparameter sets for each new solve request based on learned patterns from previous instances.Algorithm Selection Framework
The algorithm selection problem dates back to 1976 when researchers first proposed frameworks for predicting which algorithm from a portfolio would likely perform best on specific problem instances. The model comprises four essential components that work together to enable intelligent algorithm selection. The problem space P represents the complete set of instances for a given problem type. Each instance embodies unique characteristics that influence solver performance. The feature space F contains measurable characteristics extracted computationally from problem instances. These features capture essential properties that correlate with algorithm performance. The algorithm space A encompasses the portfolio of all available algorithms for tackling the problem. Each algorithm offers different strengths and trade-offs. The performance space Y maps each algorithm’s results on specific problem instances to performance metric vectors, including running time, solution quality, and resource usage.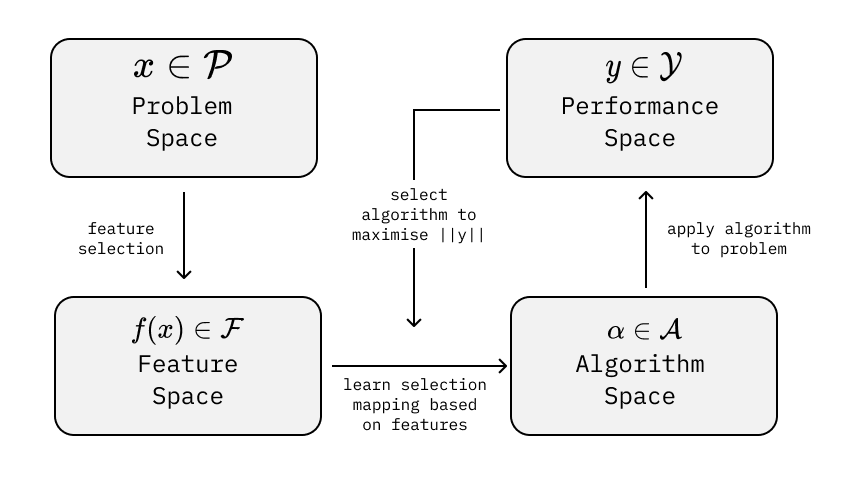
Generating Solver Data
Our platform maintains a comprehensive library of problem instances designed to cover the full spectrum of optimization challenges our solvers handle. Beyond user-generated API requests, we systematically generate instances that explore all possible problem variations. The key challenge lies in ensuring our generated instances truly represent the diversity of real-world problems. Consider the Vehicle Routing Problem (VRP) as an example. VRP encompasses numerous variations including capacitated routing, time-windowed deliveries, pickup and delivery pairs, and multi-period planning. We automatically generate instances covering all these flavors through a sophisticated feature-based approach. Rather than relying solely on structural characteristics, we use constraint definitions as primary features for instance identification. Our constraint-based feature system includes several key components. Time Window constraints define arrival time requirements for orders, specifying acceptable service windows through start and end times. Shift constraints establish driver and vehicle availability through shift start and end definitions, creating the supply side that must balance against demand from orders and their service durations. Type requirement constraints enforce skill matching between orders and vehicles, ensuring only qualified resources handle specific tasks. Capacity constraints model load requirements for orders and maximum capacity limits for vehicles, preventing route overloading. We quantify each constraint’s restrictiveness on a scale from 0% to 100%. Broader time windows provide more scheduling flexibility, while tighter windows constrain the solver’s options. This constraintness metric generates diverse instances rather than simply creating harder problems, ensuring our training data represents realistic operational scenarios.Performance Impact of Algorithm Selection
Machine learning significantly improves algorithm selection, but understanding the magnitude of these improvements proves crucial for practical implementation. Problem instance size emerges as a key discriminator in feature set definitions and algorithm performance. Traditional benchmarking strategies for VRP construction heuristics reveal interesting patterns. Greedy First Fit (FF) assignment heuristics demonstrate excellent speed and performance for small instances containing up to several hundred orders or locations. However, k-Nearest Neighbor (k-NN) algorithms dramatically outperform greedy approaches on larger instances, delivering superior computation time and solution quality. Our comparative analysis shows k-NN algorithms achieving nearly double the performance of greedy FF on large instances when measured as percentage deviation from final optimized solutions. This performance gap illustrates why intelligent algorithm selection based on instance characteristics delivers substantial real-world benefits.Real-Time Learning and Prediction
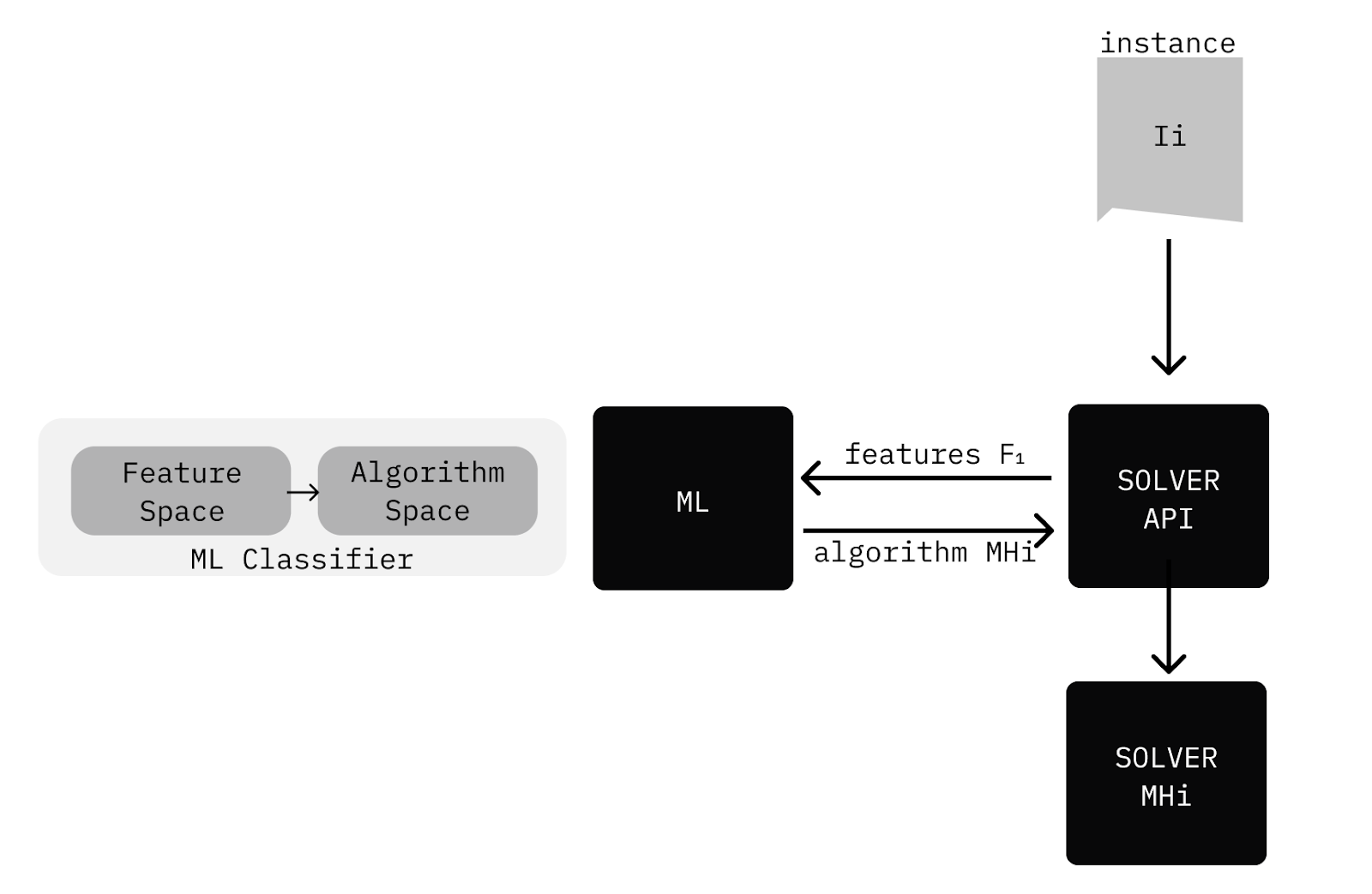
Implementing an ML layer that suggests ideal algorithm configurations requires a systematic approach. We build comprehensive problem instance datasets that capture the full range of possible scenarios. Our algorithm set includes various configurations and parameter combinations, each suited to different problem characteristics. We calculate performance metrics for every instance-algorithm combination through full factorial experimentation, identifying best-performing configurations for each scenario. The training process feeds these performance results to ML algorithms, building models that predict optimal configurations for new instances. We deploy these models in production, enabling real-time algorithm selection based on incoming request characteristics. Our categorical input variables describe instance features, while the output predicts a vector of categorical variables representing the ideal algorithm configuration. This multi-class, multi-level classification problem suits well-known algorithms such as multinomial logistic regression. The deployed system analyzes each incoming solve request, extracts relevant features, and consults the ML classifier to suggest the optimal algorithm configuration. The platform then routes the request to the appropriate solver configured with the predicted parameters, ensuring each problem receives tailored treatment based on its unique characteristics.